MoESD: Unveil Speculative Decoding's Potential for Accelerating Sparse MoE
NeurIPS🏆 Spotlight Annual Conference on Neural Information Processing Systems, 2025
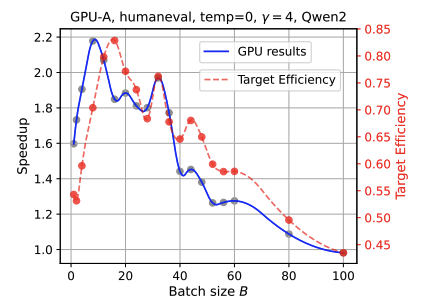
Analyze the interplay between the MoE design and speculative decoding.

I’m a Senior Researcher at Tencent AI Lab at ShenZhen, where I work with a small team that focuses on Agentic AI, especially the Long-term Memory aspect. My expertise and research intrests include: Long Context Modeling, Sparse Atention, and LLM Inference Acceleration.
NeurIPS🏆 Spotlight Annual Conference on Neural Information Processing Systems, 2025
Analyze the interplay between the MoE design and speculative decoding.
ACL Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024
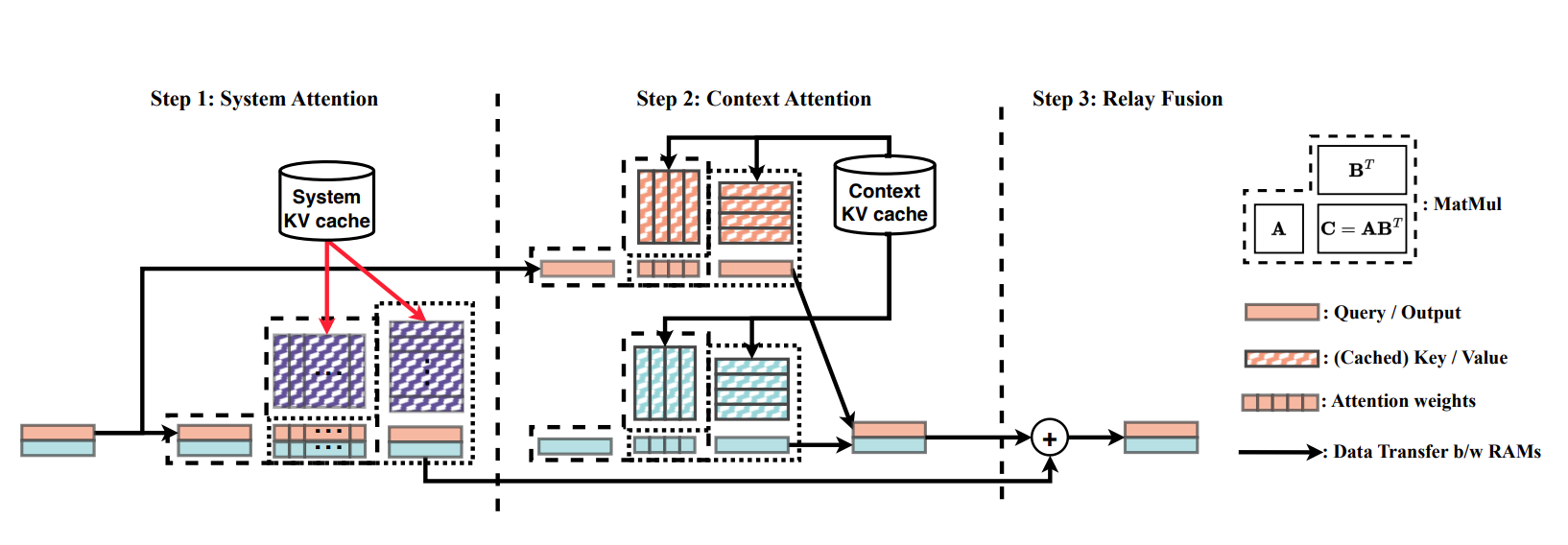
Accelerates shared prefixes for efficient LLM serving with no approximation. Concurrent works: Hydragen by Stanford U, ChunkAttention by Microsoft, Cascade Inference by FlashInfer team.
CVPR IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
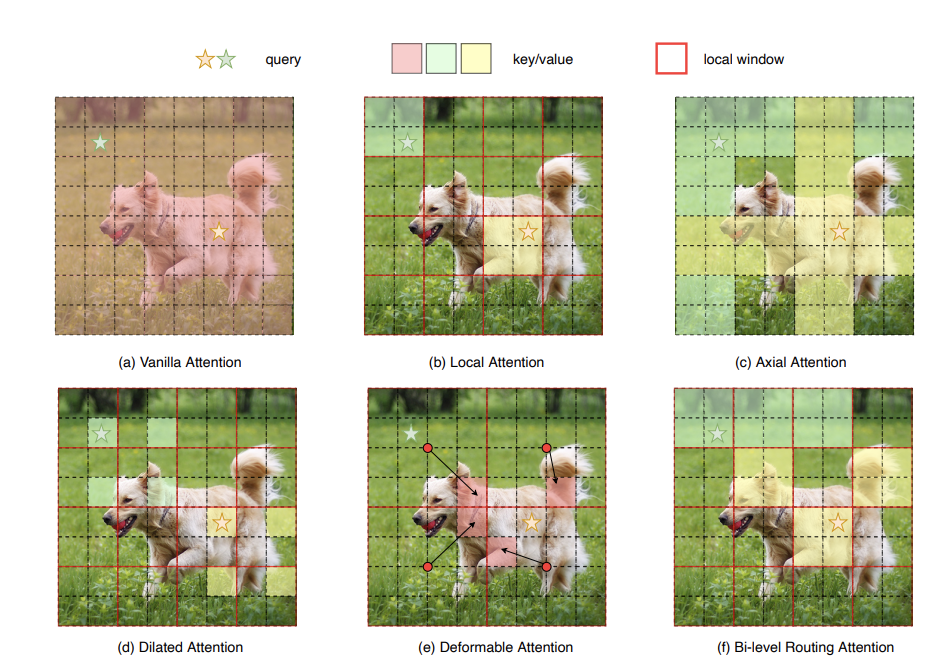
Pioneering work on introducing MoE-like dynamic block sparsity into attention. Similar ideas were later popularized by DeepSeek NSA and Kimi MoBA in early 2025.
Start my new journey at Tencent AI Lab as Senior Researcher.
One paper on MoE speculative decoding has been accepted by NeurIPS 2025 as spotlight.
We have open sourced our multi-agent deep research project DeepDiverV2 .
One paper on latency-aware test time scaling is accepted by EMNLP Findings.
Invited talk by UCSD Hao AI Lab about “Efficient Attention Mechanisms”.
Senior Researcher, Tencent AI Lab.
Senior Researcher, Huawei Noah’s Ark Lab (HK).
PhD Student, CityUHK, work with Prof. Rynson W.H. Lau .
Algorithm Engineer (Intern), Tencent RoboticsX Lab.
Research Assistant & PhD Student, CUHK, work with Prof. Eric Lo .
Bachelor in Computer Science, Dalian University of Technology.

